Introducción al Web Scraping con Python
El web scraping es una tecnica de automatización que consiste en extraer de datos de sitios web usando scripts a los que les llamaremos bots, crawlers o spiders.
Los bots o spiders pueden iniciar de una url , analizar documentos html, contenido y etiquetas con el fin de extraer datos relevantes en una base de datos o archivos.
Los bots simulan la interaccion humana, para navegar, procesar y descargar grandes cantidades de información mas rapido que hacerlo manualmente.
Preparación
Antes de hacer cualquier proyecto de web scraping hay que tener en cuenta que necesitamos saber las etiquetas y clases que vamos a buscar.
Tambien el formato en el que vamos a guardar los datos.
Ejemplos de bots mas avanzados requieren una lista de urls y una lista de posibles patrones de etiquetas para buscar, incluso la posibilidad de agregar nuevas urls en el vuelo o ejecución.
Cada proyecto de web scraping es diferente por lo cual debes guardar cada modificacion o script.
Ejemplo practico
En el siguiente ejemplo que vamos a ver como extraer los titulos de los articulos de esta misma pagina https://evilnapsis.com
Para hacer web scraping vamos a utilizar ciertas librerias, muy especificas para cada caso, en este caso vamos a usar requests y BeautifulSoup
La libreria requests sirve en general para consultar webs o navegar como si fuera el navegador. Para instalarlo vamos a usar pip.
pip install requestsLa libreria BeautifulSoup sirve para parsear documentos HTML y XML, convertirlos en un arbol de elementos de python para facilitar la extraccion de texto, enlaces, tablas etc. Para instalarlo vamos a usar pip.
pip install bs4Código
Ahora el codigo, lo voy a dejar comentado para que se entienda mejor.
import requests
from bs4 import BeautifulSoup
url = "https://evilnapsis.com" # la URL objetivo
response = requests.get(url) # ejecutamos la peticion
html = response.text # Aqui guardamos el resultado
soup = BeautifulSoup(html, "html.parser") # Inicializamos el parser
h2_titulos = soup.find_all("h2", {"class": "entry-title"}) # titulo o etiqueta o clase que deseamos buscar
# Imprimimos en pantalla los resultados
for titulos in h2_titulos:
print(" - " + titulos.text)
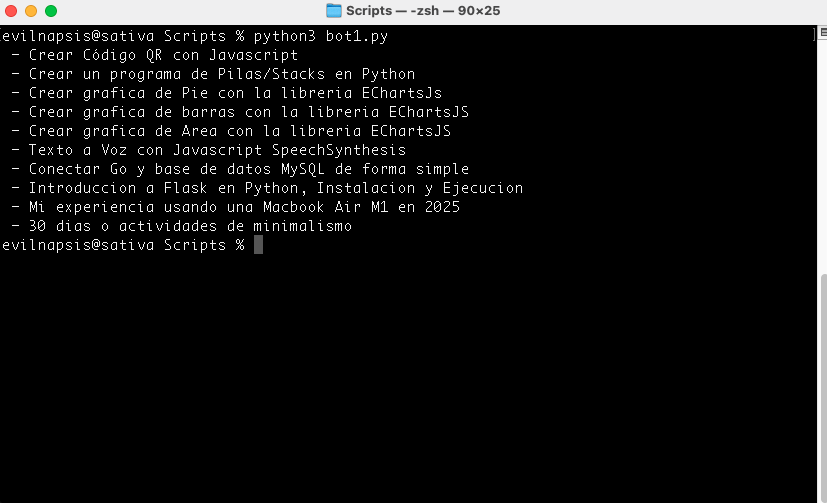
Una vez que tenemos instaladas las librerias podemos ejecutar el script, en mi caso le puse de nombre bot1.py
Este ejemplo solo va a consultar el sitio web, va a buscar las etiquetas h2 que tengan la clase “entry-title” y va a mostrar los resultados. Para ejecutar el script uso el siguiente comando.
python3 bot1.pyY este seria el resultado
Conclusion
Esta es una manera facil de hacer web scraping, pero a menudo que avanzamos en esto nos vamos a encontrar con nuevos retos por lo cual necesitaremos otras librerias y mayor potencia de procesamiento.
En general python es el mejor lenguaje para hacer web scraping pero claro que hay librerias para otros lenguajes, incluso en su momento el lenguaje PERL fue el rey del web scraping y spider webs.
Espero les haya gustado este ejemplo de web scraping con python.